Squashing DB migrations using Testcontainers
Database migrations are a standard way of dealing with database schema changes, especially in the relational world. No matter which solution we choose (e.g. Flyway or Liquibase in the Java ecosystem), the number of migrations usually grows together with the project itself. An unfortunate side effect is that the test execution time grows as well.
An effective way of speeding up our test execution in such cases is to squash (compact) all the existing migrations into a single file. This allows one to set up everything in one take and avoids performing unnecessary operations like creating and updating a table that has been removed completely later.
Flyway Teams (paid) edition comes with a Baseline Migration feature, allowing one to define a special migration containing cumulative changes until a certain point in time. When executing migrations on the fresh environment, this baseline migration takes precedence over all earlier migrations it already contains. Yet, if you can’t use the paid edition for any reason, or don’t use Flyway at all, the situation gets more complicated.
Luckily, we can achieve a similar effect using Testcontainers. In short, we can dump a fully initialized database (DB) state into a SQL file, and then inject it as an init script.
In this post, we will go step-by-step through this approach. All the examples here will use Spring Boot, and PostgreSQL, but the code would look quite similar with other frameworks and databases. The impatient ones can find a complete example on my GitHub.
The idea
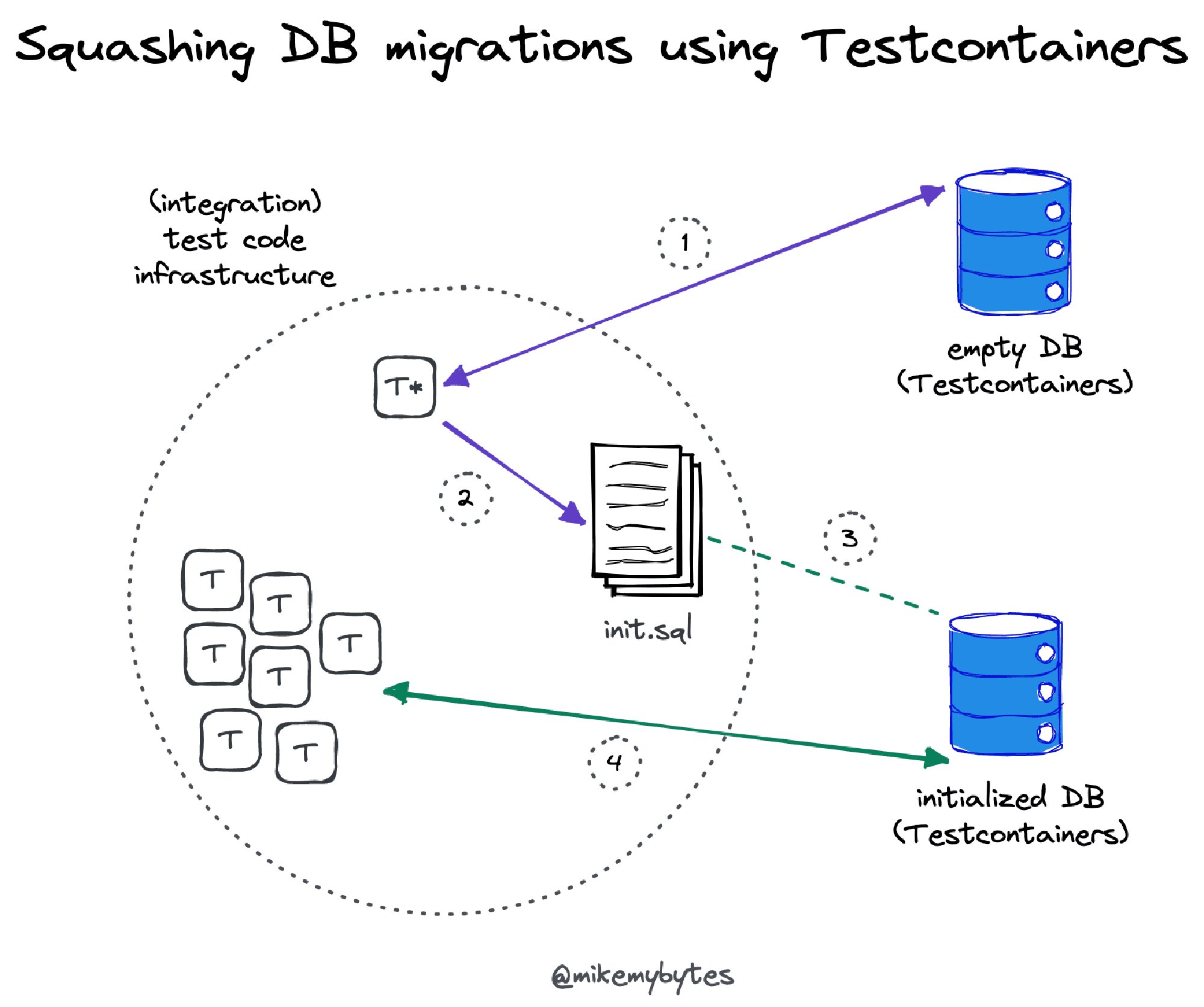
From the high level, the proposed approach looks as follows:
- Populate a fresh Testcontainers DB container with all the available migrations. Simply start the application by running a dedicated “integration test”.
- Dump container’s fully initiated DB schema into a
init.sqlfile as a set of SQL statements. This will represent the effect of appling all migrations in order. Use the dedicated “integration test” from 1. to do this for you. - Configure Testcontainers to treat the newly generated
init.sqlfile as an init script to be invoked on test DB startup (but before the container is available to the app). This settings should be then applied to all database tests. - Keep running your tests just like before. Invest the time saved on test execution into something more important than waiting 😉
Note: there’s no requirement to call the init script init.sql, but we stick to this naming for simplicity.
“Integration test” structure
As already mentioned, we will create an “integration test” to automate the process of squashing our DB migrations. In fact this will be more a code relying on the test infrastructure rather than a real test. The main benefit of this approach is simplicity - it allows to easily run all the migrations against a DB container provisioned using Testcontainers. The code looks like this (full source available on GitHub):
// @Disabled // 1
@SpringBootTest
@Testcontainers
class SquashDbMigrationsManualContainerManagementTest {
@Container // 2
private static final PostgreSQLContainer postgres =
new PostgreSQLContainer(DockerImageName.parse("postgres:15.1"));
@DynamicPropertySource // 3
static void registerPgProperties(DynamicPropertyRegistry registry) {
registry.add("spring.datasource.url", postgres::getJdbcUrl);
registry.add("spring.datasource.username", postgres::getUsername);
registry.add("spring.datasource.password", postgres::getPassword);
}
@Test
void squashDbMigrations() {
// 4
var dump = PostgresDumper.dump(
postgres.getContainerId(),
postgres.getDatabaseName(),
postgres.getUsername(),
postgres.getPassword()
);
// 5
InitSqlUpdater.write(dump);
}
}
Let’s quickly summarize all the steps:
- Despite being a part of the test code, our “test” should only be run on demand. That’s why it’s annotated with
@Disabled(1), which requires commenting out each time we want to squash our DB migrations. Such “run on demand” approach could be also implemented differently (e.g. using JUnit 5 conditional test execution), but this exceeds the scope of this article. - We’re creating PostgreSQL instance manually (2). This way we can get an access to the underlying container ID easily. This identifier would be crucial for connecting into the running DB container.
- We’re setting up a connection between our test app and the DB which requires providing required properties (3) - JDBC URL, username, and password.
- At the time of test method execution (4), our DB instance has all the migrations already applied. We can now call
PostgresDumperto get the SQL commands, and simply write them into thesrc/test/resources/init.sqlfile (5).
Alternatively, the database container could be launched using special JDBC URL. When using this approach, the ID of the running DB container has to be obtained differently. What I proposed is to use DockerClient API to do this. You can find an example on my GitHub.
Ideally, we should run our squashing “test” every time we add a new database migration to our codebase. However, this is not mandatory. Migrations made after the previous squashing will simply be applied one by one. In other words, such compaction makes sense even if it’s not done on a regular basis.
Dumping the DB schema
It’s time to take a closer look at the PostgresDumper class. What it does is it connects to the running DB container using DockerClient and then dumps its content as a set of SQL commands. Instead of reinventing the wheel, we can simply use the built-in PostgreSQL pg_dump utility.
It’s crucial to invoke pg_dump with --inserts flag. This ensures that the dump will not use COPY command which seems to be unsupported when used from within the init script (causing ERROR: COPY from stdin failed errors).
public static String dump(String postgresContainerId,
String dbName,
String dbUser,
String dbPassword) {
var dockerClient = DockerClientFactory.instance().client(); // 1
var response = dockerClient.execCreateCmd(postgresContainerId) // 2
.withAttachStdout(true)
.withEnv(List.of("PGPASSWORD=\"" + dbPassword + "\""))
.withCmd("pg_dump", "-U", dbUser, dbName, "--inserts")
.exec();
var stdoutConsumer = new ToStringConsumer();
var stderrConsumer = new ToStringConsumer();
var callback = new FrameConsumerResultCallback(); // 3
callback.addConsumer(OutputFrame.OutputType.STDOUT, stdoutConsumer);
callback.addConsumer(OutputFrame.OutputType.STDERR, stdoutConsumer);
try {
dockerClient.execStartCmd(response.getId())
.exec(callback)
.awaitCompletion(); // 4
} catch (InterruptedException e) {
throw new IllegalStateException(
"Interrupted while awaiting command output from Docker", e);
}
var dump = stdoutConsumer.toUtf8String(); // 5
assertThat(dump).contains("PostgreSQL database dump"); // 6
var now = LocalDateTime.now();
var header = "-- Generated with <3 using Testcontainers at " + now;
return header + "\n\n" + dump; // 7
}
Let’s go step by step through the code. After obtaining DockerClient instance (1), we are invoking pg_dump (2) passing required credentials and the --inserts flag. In order to read the generated SQL code, we have to connect the the stdout using dedicated callback. The first call gives us only an ID that we have to pass to the DockerClient instance and await command’s completion (4). Once it’s done, the SQL code can be obtained from the stdoutConsumer. At this point we can do additional things like verifying dump’s correctness (6) or adding a custom header (7).
Running tests with squashed migrations
Once we run our squashing machine, the init.sql file should contain the complete state of a fully initialized database. Now we can use it for speeding up test execution process. Enabling the init script will look a bit different depending on how we’ve set up Testcontainers DB container for our tests.
When managing the container manually (similarly to what has been presented before), we can pass it using withInitScript function:
@Container
private static final PostgreSQLContainer postgres =
(PostgreSQLContainer) new PostgreSQLContainer(
DockerImageName.parse("postgres:15.1")
)
.withInitScript("init.sql");
When using automated container management via JDBC URL, we have to set the TC_INITSCRIPT param. As we probably want to speed up all our test, this configuration could be stored within the application.yml/application.properties file. Yet, we can also enable it using annotations:
@SpringBootTest(properties = {
"spring.datasource.url=jdbc:tc:postgresql:15.1:///test?TC_INITSCRIPT=init.sql"
})
What’s worth mentioning, supporting stored procedures or triggers may require a bit different approach to providing the init file. Instead of withInitScript, the init.sql file should be copied to the container using withCopyFileToContainer into the special /docker-entrypoint-initdb.d/ directory. As this is specific to PostgreSQL Docker image, I’d recommend trying with the standard init script first.
Is it worth it?
There’s no doubt, that the described approach introduces additional complexity to the code. Are the gains worth the effort? As always, the answer is “it depends”.
Intuitively, the more migration files a project has, the more significant the gains should be. To verify this assumption, I picked the migration files from two real-life projects with 35 (Project A) and 50 migrations (Project B) files and then apply them in a controlled environment. The results were as follows:
- Squashed migrations from Project A (35 files) - around 64% speedup (~500ms)
- Squashed migrations from Project B (50 files) - around 20% speedup (~1700ms).
As you can see, the final impact will differ across projects. It’s not only about the number of migrations, but also what they do.
When the number of migrations is low, this approach may be overkill. Yet, it’s hard to define a precise threshold here. My advice would be to not implement this approach from day one. In the early project stages test execution performance is usually more than satisfying.
The presented approach could be a game-changer, especially in all the systems that were growing for a couple of years and are already running on production. For these systems, squeezing migrations outside of the test code (squashing existing migrations manually) is probably no longer an option.
The more times you initialize an empty DB for tests, the more impact squashing migrations will have. When reusing the DB container across tests, saving a second overall may not feel much. However, executing tests from an IDE (unless using reusable containers) will still initialize the DB every single time. In my opinion, this is something worth fighting for.
Next steps
The migrations squashing process could potentially be automated. Instead of using @Disabled, our special “integration test” could use JUnit 5 system property conditions. This special system property could be then set by a dedicated CI pipeline (e.g. GitHub Actions), running the test and committing the results for us. Such pipeline could be run after adding new migration file to our codebase.
Those looking for extreme solutions may want to embed the result of migrations directly in the DB container. With init.sql file already in place, it’s possible to build your own PostgreSQL Docker image with the script (migrations) already applied.
Eventually, one may consider using the init.sql file for provisioning new environments. This would probably require adjusting some of its content like the schema name and its owner (user). Although possible, I’d rather use it as a last resort option due to the risk of a costly mistake.