JSON, Kafka, and the need for schema
When I started my journey with Apache Kafka, JSON was already everywhere. From Javascript UIs, through API calls, and even databases - it became a lingua franca of data exchange. For many organizations adopting Kafka I worked with, the decision to combine it with JSON was a no-brainer.
Yet, this post is not really about Kafka itself. It’s not another how-to guide either. Using Kafka made me less enthusiastic about JSON and more focused on data evolution aspects. Here, I’d like to share some of my observations with you.
As always, the context matters. Unless specified explicitly, I’ll refer to one specific use case: exchanging structured messages between services.
Messages are getting old
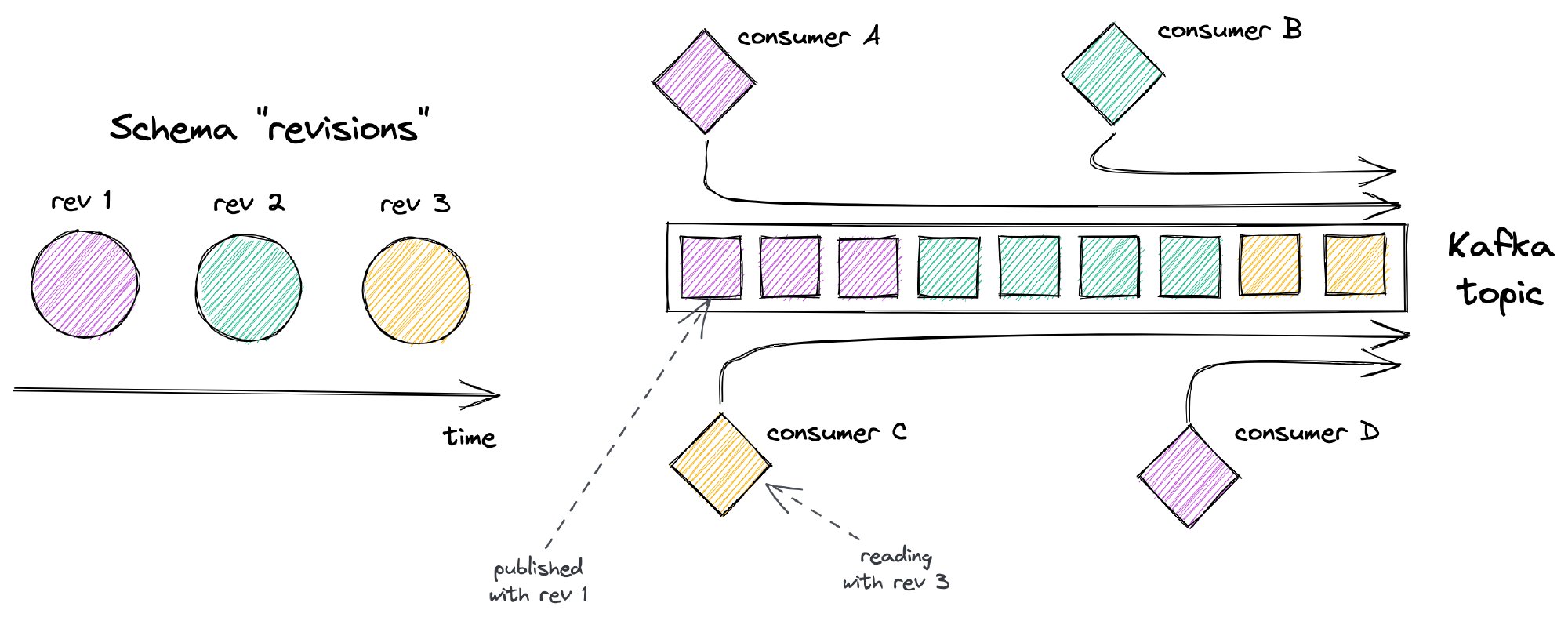
The one thing you have to know about Kafka is that messages published to it are not being removed after reading. In fact, the broker doesn’t care about that aspect at all. It’s the retention period that defines how long (time or size-wise) messages from a certain topic should be available for consumption. Furthermore, defining topics with unlimited retention (storing messages forever) is not unusual too. As a result, messages last longer than the specific consumer versions.
This property has consequences for altering message structure. As we have to deal with both: the existing and future consumers, we also have to consider the compatibility aspects. To be fair, this is not a brand new problem. When using synchronous communication (like REST) we may also run into similar issues. Yet, there’s a slight difference here. Updating all the existing consumers is not always enough. Newer Kafka consumers introduced later may still try to read the log from the beginning and fail on the incompatible messages.
This makes every structure-related mistake more painful. Before you even realize it, incompatible messages are flooding your Kafka cluster. If you’re already in production, simple solutions like wiping all data and starting from scratch are no longer an option.
The hell of flexible notation
Flexibility is usually desired. Yet, it could also create more problems than it solves.
All the projects using JSON as a data exchange format (not only with Kafka) have something in common. There’s a “standard” set of questions, that must be asked sooner or later, like:
- How to encode decimal numbers in order to prevent accuracy loss?
- Should we encode dates as timestamps or as ISO-compatible strings?
- Should we send
nullfor every empty field, or simply ignore it? - How to encode binary data?
Although there are many guidelines available, it still feels like a never-ending series of discussions and debugging. Don’t we have more important problems to focus on?
Take a look at this innocent example:
{
"name": "Jason",
"salary": "12345.67",
"bonusRatio": 0.17,
"hired": "2020/06/07",
"lastEvaluation": "2022-01-18T13:07:17Z",
"updatedAt": 1654948498
}
Questions like “does ‘2020/06/07’ mean June or July?” may sound funny, but it’s not uncommon to end up with such a mess in a real-life project.
JSON really shines when data flexibility is required, thanks to its schema-less nature. It allows us to keep accepting data without worrying too much about what’s inside. While this works well in certain use cases (including Kafka!), it could become painful in others. When exchanging structured messages between services, having a schema is usually a reasonable choice.
JSON Schema was born to fill this gap by introducing schemas for JSON documents. It allows not only to describe and validate the structure of the document, but also comes up with a consensus on some encoding aspects. So does this mean that we have a solution for all our problems already in place?
Adopting JSON Schema is a decision similar to answering the “JSON questions” I’ve mentioned before. It’s not a “take it or leave it” for JSON itself. That’s why it may feel like something that could be easily introduced later. Unfortunately, the reality is usually different.
What’s interesting, I’ve seen a lot more adoption of the Open API (Swagger) specification for REST APIs, than JSON Schema for Kafka messages. Do we underestimate the power of schemas in certain contexts? Well, I think there might be just more people familiar with REST than those who are comfortable with Kafka.
Data keeps evolving
Encoding aspects are only one side of the coin. Another problem is that the data we’re producing is evolving over time. We keep extending our messages, changing their structure here and there, as our consumers have new expectations. The main challenge is ensuring compatibility across all our existing and future consumers. That’s where the schema evolution comes into play:
you can change the schema, you can have producers and consumers with different versions of the schema at the same time, and it all continues to work ~ Martin Kleppman
The schema evolution process is about ensuring certain compatibility guarantees, by preventing breaking changes. Together with proper tooling (like Confluent Schema Registry or buf), we can easily enforce them programmatically. There are several types of these guarantees, including:
- backward compatibility (consumers using the new schema can read data published with the older schema)
- forward compatibility (data produced with a new schema can be read by consumers relying on previous schemas)
- full compatibility (backward + forward).
This is a huge topic of its own, far beyond the scope of this article. Yet, preserving full compatibility feels like a reasonable and safe default to me.
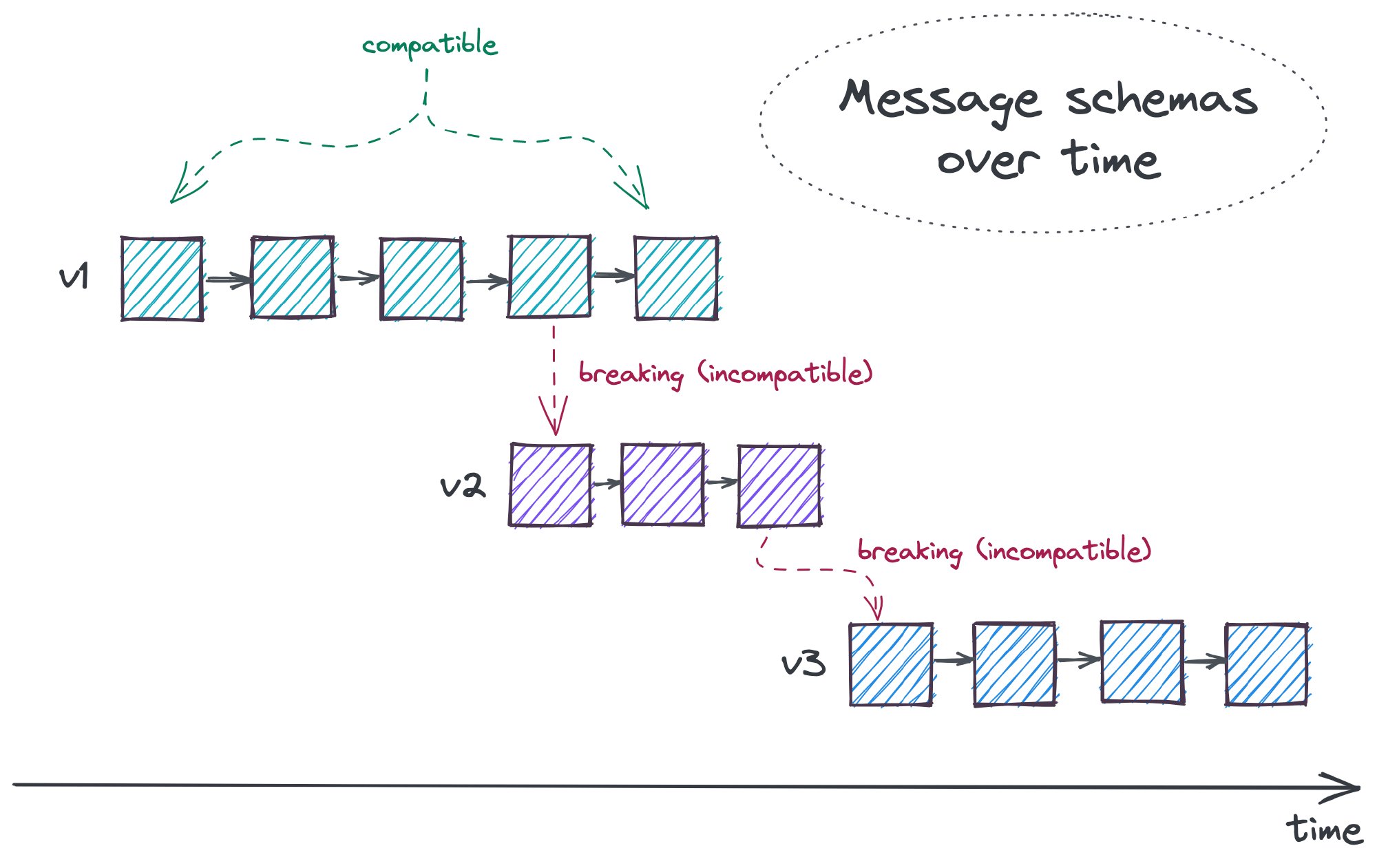
There’s a slight difference between schema evolution and versioning (where data in different versions are stored separately). With the latter, each version (v1, v2, …) represents a different, potentially incompatible message structure. Once the changes are needed, a new version is created. Then, the producers usually have to keep publishing multiple versions at the same time. When there are no more “old” consumers, the support of outdated versions can be dropped. Such a migration process is often gradual and time-consuming. It requires proper communication and strategy. Yet, it allows us to (eventually) forget about past modeling mistakes, and start anew.
Schema evolution gives us an alternative. As long as the changes don’t break the compatibility, they can be introduced immediately. This is especially important for distributed systems being built by multiple teams. It can reduce the burden of communication and the need for synchronization. In other words, schema evolution allows making compatible changes between incompatible versions.
Modern serialization formats like Protobuf or Avro provide built-in support for schema evolution. Techniques like Avro aliases, or Protobuf types compatibility give us additional flexibility. One could say that their encoding rules encourage introducing compatible changes.
On the contrary, JSON Schema evolution is different. To me, it feels more cumbersome and “manual”. That’s why, while it’s possible to implement proper schema evolution with JSON Schema, I’d still prefer Avro or Protobuf.
There’s one additional thing that should be emphasized. Mentioned formats usually require additional tooling to enforce certain compatibility guarantees. In the Kafka world, a typical solution is to introduce a Schema Registry. However, adding an additional infrastructure component like this may not always be required.
May 17, 2022Compatible format != compatible semantics
Formats like protobuf focus on msg structure, but they don't free the pub-sub producers from thinking about their meaning! Downstream consumers may break (silently!) due to misinterpretation.May 17, 2022
A story about tolerance
Not all people get convinced by schemas, though. Some feel that related serialization formats are just too much for their use case. It’s hard to argue with the additional complexity they bring to the early stage of the project. Besides, Kafka tutorials using plain JSON just feel less overwhelming. Especially with Avro, reducing moving parts (Schema Registry) feels like a good idea at first. Yet, it doesn’t mean that the problems described in previous sections will disappear.
Do we have any alternatives? I’ve seen different DYI approaches in the past, including:
- YOLO 😎 (“keep producing, it’s the consumer’s problem now!”)
- “Let’s do it right from the beginning” 🤞
- Introduce a dedicated “gatekeeper” 💂 reviewing all messaging-related changes across all services and teams(!).
I could probably write a separate article just explaining why these didn’t work well…
There was also one approach that looked really promising at first, which made its failure even more disappointing. Have you heard about the Tolerant Reader Pattern (TRP)? In the nutshell, it is closely related to Postel’s Law:
be conservative in what you do, be liberal in what you accept from others.
When describing TRP, Martin Fowler brought XML as an example:
My recommendation is to be as tolerant as possible when reading data from a service. If you’re consuming an XML file, then only take the elements you need, ignore anything you don’t. Furthermore make the minimum assumptions about the structure of the XML you’re consuming. Rather than use an XPath search like /order-history/order-list/order use //order. Your aim should be to allow the provider to make any change that ought not to break your code. A group of XPath queries are an excellent way to do this for XML payloads, but you can use the same principle for other things too.
Not making unnecessary assumptions is indeed great advice. But what about this additional flexibility? Isn’t that a bit risky in the long run? When taken to the extreme, TRP could be misinterpreted as a simpler alternative to schemas. In short, it’s now the consumer’s responsibility to not fail on messages that look unusual.
From my experience, this does not seem to age well. Teams maintaining consumers have to actively track changes on the producer’s side. Without automation’s support, they have to rely on team-to-team communication and writing defensive code. We all know, that communication is challenging, but what’s wrong with defensive coding?
Something that starts as a bunch of if-else constructs, may soon turn into an unmanageable spaghetti. Some checks will be added upfront, based on the discussions with the producers. Others will be added as a remedy for issues discovered during day-to-day operations when it might be already too late to do things right. But, what’s even worse, deleting them later would be extremely risky. Since there’s no tooling support, one would have to run an investigation first and then just take the risk, keeping their fingers crossed… Oh, and every consumer app could end up with a different set of such checks!
In my opinion, these “lightweight” approaches should not be considered as a real alternative for the proper schema evolution process. Despite the complexity it brings, schema evolution is not just another fancy thing you should have. Therefore, trying to get rid of it can quickly become a dead end.
Life after JSON
One could think, that I claim it’s impossible to use JSON right. That’s far from being true. JSON is still one of the most widely used data formats in the world for a reason. I simply believe that in certain use cases we can do better. Especially, when having a schema is the way to go.
When picking a data format for structured messages, I’d like to avoid constant discussions about the details. Instead, I’d pick an opinionated one, built around the schema evolution concept. For exchanging messages, I’d prefer a schema-first approach.
Last but not least, I’d also like it to be efficient and performant. People often focus too much on the performance when comparing JSON with binary encoding formats. The truth is: one can always pay for more CPU and memory, but can’t buy proper data management. Yet, this aspect should not be ignored - especially at a large scale.
You may be surprised that I don’t discuss human readability aspects here. To be honest, I no longer feel it’s a serious advantage in this context. We should promote effective (binary) communication between the computers, instead of eavesdropping on them. In fact, the only thing that still benefits from human readability is the schema definition itself.
Formats like Protobuf or Avro are no longer new on the market. As more and more companies are adopting modern serialization techniques, the related tooling gets better. Especially in the Kafka world, these formats feel like a standard part of the ecosystem now.
What’s interesting, both of them have a notion of JSON compatibility. Protobuf allows mapping messages to JSON and provides an API for the conversion process. Avro goes a bit further by having a JSON-like data model and using JSON for schema definitions. Of course, the mapping to and from JSON is also there. Yet, in both cases JSON feels a bit like a “side effect”, acting as a bridge between the two worlds.
Taking all of this into account, I consider formats like Avro and Protobuf as better alternatives when exchanging structured messages between services. No matter which one you choose, it’s gonna be a significant step forward compared to plain JSON. And if you ask me, I’d probably pick Protobuf due to its simplicity - but that’s a topic for yet another discussion 😉
Summary
Using Apache Kafka in several organizations and projects, made me realize that schema evolution is a must in certain contexts. One of them is exchanging structured data between services. In light of all the encoding issues and a bit cumbersome JSON Schema evolution, I feel that sticking to JSON may no longer be a great idea. Switching to the modern serialization formats like Protobuf and Avro gives both instant and long-term advantages. When starting a project from scratch, introducing schemas from day one may feel like a significant investment, but it should pay off really quickly.