Go-live is a test of flexibility
We want our applications to be maintainable, reliable, resilient, and scalable. All these features seem to share the same idea: being flexible. This flexibility is often manifested in the early design documents close to the buzzwords and technology names. But that’s only the marketing. The true test of flexibility comes with the first go-live. “Production will verify” as my former colleagues used to say.
Flexibility is usually a good thing. It means being able to adapt. Bending without breaking. Flexibility gives us a margin of error when something unexpected happens. Just like it was “made” with production in mind.
The amazing place called “production”
Production is my first favorite place on the internet. I love production. You should love production. Go as early and often as possible. Bring the kids. Bring the family. The weather is amazing. It’s the happiest place on Earth. It’s better than Disneyland!~ Josh Long (@starbuxman)"97 Things Every Java Programmer Should Know", O’Reilly 2020
There is no other place like production. This is where hours of planning, design, and implementation should finally pay off. But they don’t always do. Going live is the ultimate test of all the choices and assumptions.
Production is the only place where we actually see how all the pieces of our system fit together. It’s also where these little “improbable” things really happen. It’s a place full of surprises, where Murphy’s law is like gravity, no matter you like it or not. As we can’t foresee everything, flexibility becomes our insurance policy there.
Flexible configuration
One of the most important lessons from the Pragmatic Programmer book is to separate configuration from the code. Containerising apps has reminded us about this idea. We build the app (container) only once and provide the environment-specific configuration externally.
Flexible configuration should be the first way to deal with unexpected troubles. Heavy traffic? Scale-up! Too much load on scheduled tasks? Change their frequency. Caching not working as expected? Try setting cache size to zero. Some of the issues could be directly solved this way without making a single change in the code. Sometimes a small configuration change could buy you some precious time ($$$) until the fix will be ready.
Usually, performance-related settings may be picked reliably only based on the real, production load. Making them configurable at runtime gives us the opportunity to tune our system on demand - similar to changing Java heap size.
Configuration should be composable. Let’s take the Spring Boot as an example. All the “boring” defaults are hidden, but we still can override selectively whatever we need. We can define a common set of overrides, but still provide some environment-specific settings on top of them. This way we keep the configuration small and focus only on the app-specific aspects.
However, every configuration entry comes with a cost. Even if adding new entries is relatively easy in modern frameworks, it still brings additional complexity to the code. New conditional branches they introduce (especially for on/off toggles) have to be carefully tested.
Feature flexibility
All the non-trivial systems have more than one feature. Sometimes they are domain-specific logic, at other times they provide a connection to the outside world (e.g. API or user interface). Let’s call them internal and external features. The latter will usually benefit from the flexibility the most.
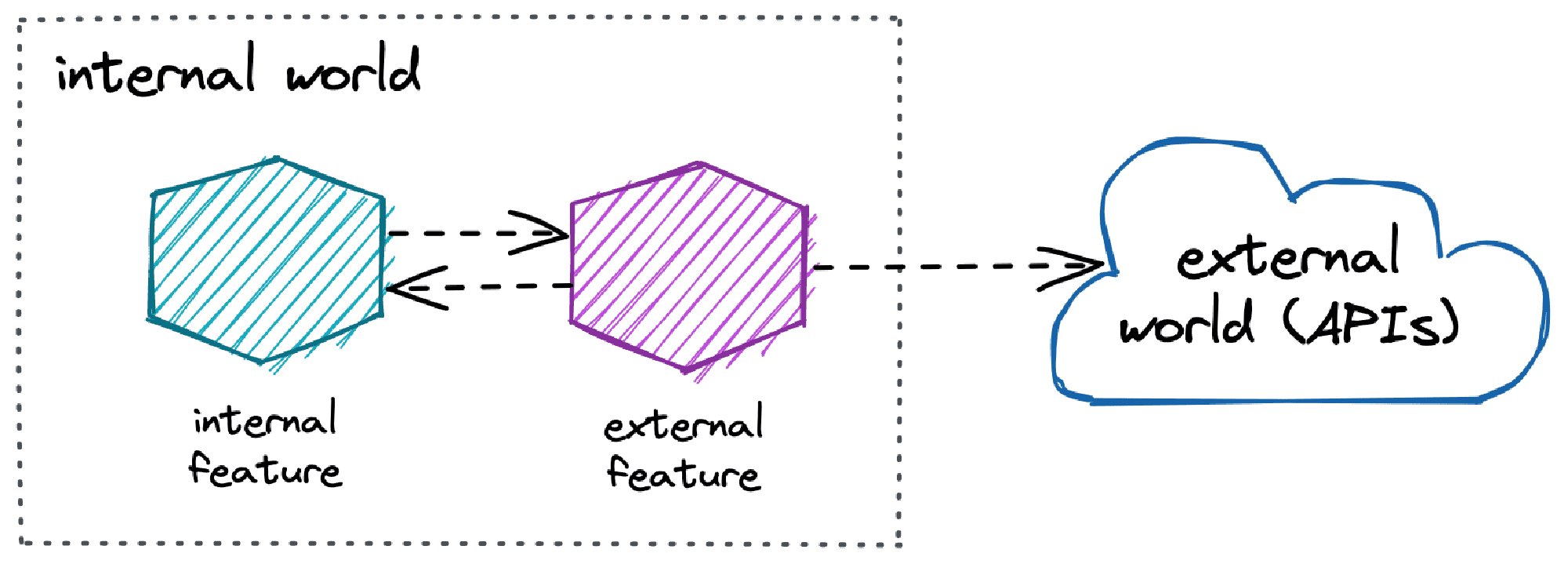
Imagine the invoicing app that is also supposed to send an e-mail with the generated invoice file. A networking issue (preventing from sending a message) should not block the process of generating the invoice itself (internal feature). Additionally, in case of mail server downtime, we may want to avoid timing out our requests to avoid cascade failure of the system. No matter if the mail server is under our control or not, something will eventually go wrong.
Being able to disable an external feature is usually worth the effort and complexity of adding a new feature flag. In case of issues, we can quickly pull out the plug and wait for better times. When encapsulating external interactions, queues and asynchronous communication are our best friends.
Fixing own mistakes
Some features are just data processing pipelines - data in, data out. When we realize that our pipeline is wrong, it’s usually too late. The code has been already deployed, data have been already processed, etc. While test environments could be easily re-created, we can’t ignore the production data.
July 29, 2021Updating production DB manually is like playing Russian roulette. The difference is you play at work, risking someone else getting shot because of you.July 29, 2021
If our design is flexible enough, we may still be able to recover by re-processing original data. There are many ways to achieve that, including:
- storing original input data in the DB (for re-processing),
- preserving (and then replying) the history of events (messages),
- consuming the data from a DLQ (if faulty records have been rejected before).
Recovering gracefully from the data processing-related issues can be a huge advantage. Yet, it comes with a usual cost of extra complexity. There’s probably no point in applying such techniques for simple applications like CRUDs.
Not every PROD is the same
To know how much flexibility is enough, we first need to understand our production environment. Usually, the longer the development cycle is, the more flexibility you need to survive.
In restricted environments deploying a new version out of the maintenance schedule may simply not be an option. NASA takes this idea to the extreme when sending its machinery into space. In 1997, the Mars Pathfinder spacecraft has been debugged & patched remotely thanks to the built-in C language interpreter. Such an approach is indeed really flexible, but also extremely expensive.
As most of us don’t send apps into space, we should think about how much flexibility is really needed. Redundant flexibility may result in a brittle and complex system with high maintenance costs. Keeping it too low may result in a painful lesson during the next incident.
Frequent deployments are also a sign of flexibility. Since they allow us to adapt more quickly, we may not need extreme configurability at the same time.
Summary
- Being flexible enough is a key to dealing with the unexpected. Since the production environment is full of surprises, flexibility becomes extremely important there.
- Separating configuration allows changing the application’s properties without changing the code. By making it composable, some settings could be changed whenever needed.
- Features relying on the external world (e.g. APIs) are usually worth wrapping with a dedicated flag to disable them on demand. Techniques like asynchronous communication can help to deal with many kinds of failures.
- In the production environment, we have to pay special attention to the data. If something will go wrong, we may need a way to re-process them.
- Deployment frequency implies the desired flexibility level.