SLA is the new CAP
The world has changed quite a lot since 1999 when Eric Brewer formulated his famous conjecture, known as the CAP Theorem today. Back then, the systems were running mostly on a self-hosted and rather expensive infrastructure, often related to the software components in use (due to licensing, etc.). A proper understanding of availability & consistency trade-offs in the presence of network partitions was simply yet another responsibility on the list.
Today, SaaS/PaaS/IaaS products have distracted us from many of those problems, while leaving promises of a carefree life focused on our business instead. After more than 20 years, SLA (Service-Level Agreement) became the new CAP, defining the limits of the distributed systems we are building.
CAP is only about the 3 of them
Describing a distributed system only through its consistency, availability, and partition tolerance may look appealing on a triangle, but only scratches the surface of the important design decisions and guarantees. The CAP Theorem says absolutely nothing about the aspects like durability (what will happen with the data in case of failure) or latency (and performance trade-offs in general), that may turn out to be even more important from a practical point of view.
With as-a-service products, we usually treat each service a bit like a black box, expecting certain guarantees no matter how they have been ensured internally. Unlike with CAP, we are no longer bound only to the original three properties, so (in theory) we can choose a product better suited to our business needs. We may look for specific numbers being a part of the SLA (known as the Service Level Objectives) related to things like uptime, maximum response times, or data durability. Unlike the traditional, self-hosted solutions, it is solely the service provider’s responsibility to keep those promises.
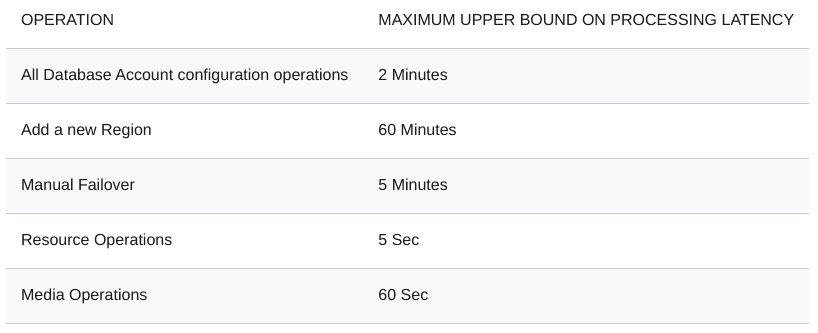
For example, Azure Cosmos DB SLA defines not only availability guarantees, but also specific measures for throughput, latency, and even consistency (interestingly, understood as the availability of operations with a certain consistency level).
Of course, the reality is far from being perfect. Not every provider will eagerly take the risk of defining precise numbers for all the metrics we need. Even so, we could get something difficult to measure or reason about, just like Amazon S3 99.999999999% durability. What’s even worse, in the majority of cases, the only consequence of not meeting the promised guarantees would be a discount on our bill. That’s why we still have to read the fine print carefully.

We really care about the availability
Interestingly, out of all the distributed system properties, we care the most about the availability, as in every system it may change over time. In other words, the system may be more available in one day than in another, while we can’t afford similar trade-offs for things like consistency.
The CAP Theorem assumes the system being always available for all operations, completely removing node failures from the equation. In reality, we not only have to take them into account but also be aware, that such a 100% of availability is a utopia. That’s why Google Spanner explicitly chooses high availability instead as the only realistic goal.
June 16, 2021"Even when there is no fear of failure, there will be a failure" ~ anonymous #DistributedSystems engineer https://t.co/KXmRY4Y6vVJune 16, 2021
Distributed systems should always be prepared for external services unavailability, which is no different when using as-a-service solutions. This simple observation has important consequences for both service providers & applications using their products. Effectively, various different problems (including hardware failures or network partitions) are visible to the application simply as a downtime. This makes the availability a perfect rug to sweep the issues under, simplifying the SLA and the application code.
Such a casual approach to the availability aspects may sound worrying especially to the end-users. However, the statistics is on their side thanks to the effect called differential availability. In short, the effective system availability may be even higher than the one calculated only based on service uptime. Explanation? We won’t notice service unavailability unless we will try to use its unavailable part exactly when it’s down. Since such issues usually don’t last long, the probability of such a “collision” is relatively low.
SLA is a bit more practical
Over the years, the CAP Theorem has been heavily criticized for its limitations and narrow scope of interest. On the other hand, there is no doubt, that it’s a fundamental law of building distributed systems, that heavily influenced the design decisions behind thousands of applications - including popular as-a-service solutions. However, from their users’ perspective, CAP-related details may not be very important.
Let’s take Amazon S3 as an example. At the end of 2020, the S3 team has announced “strong read-after-write consistency”. Despite some clarification attempts, at the time of writing it is still unclear, whether this means the same as CAP’s consistency (defined as linearizability) or not. Does this impact S3 users? Most probably not, since certain sematic (in this case read-after-write for all PUTs and DELETEs of objects) seems to be more expected than a formal proof.
Moving back to the self-hosted systems, the theoretical guarantees being a consequence of the specific CAP characteristic should be considered only as best-effort goals. Things like infrastructure setup or service configuration not only require a lot of effort but also define realistic limitations on what could be expected. Additionally, we may quickly realize that we don’t have as much operational experience & resources as some big cloud providers do. But that’s a whole different story…
Summary
Although the CAP Theorem is not going to retire, it seems that its importance has dropped at least in some practical aspects. In the meantime, the SLA (along with related SLOs) has taken its place as the main model defining limits of the distributed systems available in the as-a-service model. Of course, the SLA itself is also far from being perfect, but it’s probably the best we can have in the cloud-based world.