How startup time affects reliability
There seems to be a lot of interest in improving application startup time these days, driven by the discussions on languages and technologies (like Go, Node, or GraalVM), that provide almost instant startup for serverless functions (a.k.a. lambdas) being run in the cloud. However, such a speedup brings benefits to other types of processing as well.
In this post, I’d like to present a different perspective on the topic of application startup time. Instead of focusing on serverless functions, I will show how faster startups can improve the reliability of a more “traditional” distributed system.
Exploring the limits
Imagine a service A scaled to the 4 identical instances A1, A2, A3, and A4. Assuming that we have proper load balancing in place, the total of X concurrent requests should be distributed across all the nodes more or less equally, so every instance has to deal with X/4 of them (assuming that uniform distribution is possible).
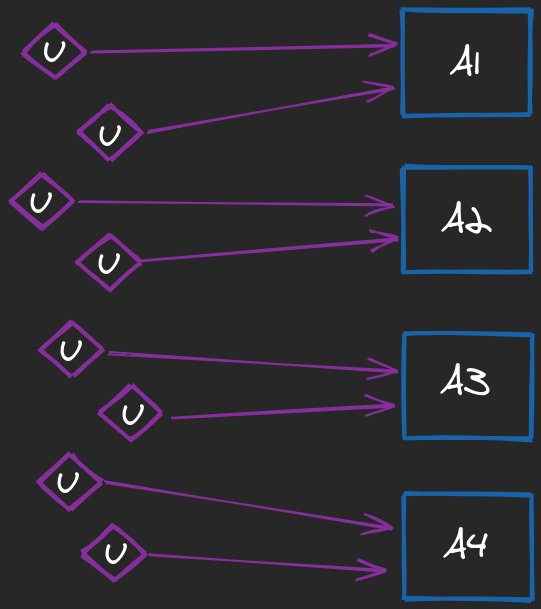
Every node has a maximum number of concurrent requests it could handle gracefully - let’s call it Z. Unless some additional countermeasures will be taken, starting from Z+1 concurrent requests the instance may experience various problems, eventually leading to a failure, including:
- Insufficient resources (running out of memory, available threads, etc.)
- Significant overhead on garbage collection (GC) leading to performance degradation or even application unresponsiveness (e.g. with stop-the-world GC pauses in JVM)
- Increased response times, that may lead to timeouts on the client-side or incorrect marking the instance as dead (e.g. because of the liveness probe not responding on time)
- Cascade failures of the dependent services (e.g. with blocking communication, a caller of the A’s API may quickly run out of available threads).
The Operator (person or an orchestrator process) would most probably react to such a situation by simply restarting the misbehaving instance or/and spinning up an additional one. Problem solved? Not really - in fact, this is where the startup time matters the most.
Scenario #1: Instance down
Let’s examine the case when the Operator decides to restart the problematic instance A1. Until now, every instance of service A was handling X/4 concurrent requests. After killing A1, the remaining three have to deal with an additional X/4 together. This means each remaining instance has now up to X/12 (~8.3%) more requests to handle. Of course, uniform traffic distribution may be impossible, leaving some nodes more occupied than the others.
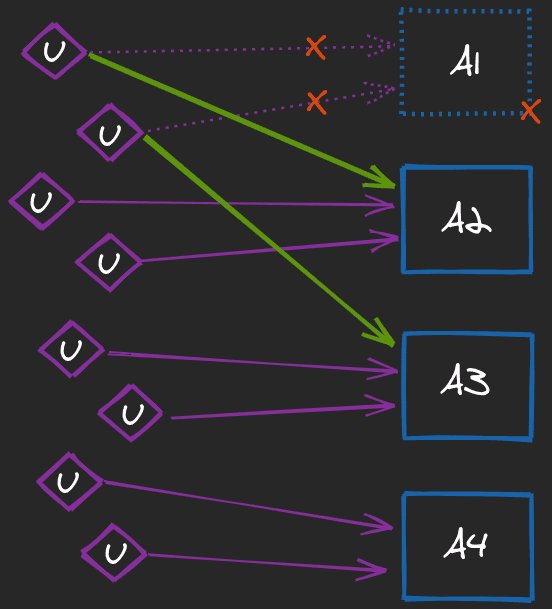
The reason why A1 has been killed was simply too much traffic coming in. With additional X/12 requests on some nodes, we may immediately hit the limit of Z on them too. For example, if another instance (A2) will also fail, the remaining two will have to deal with twice the workload than under normal circumstances (quickly exceeding the Z limit too). As you can see, this scenario is a simple recipe for a failure of multiple instances at once.
The system is the most fragile while waiting for new instance(s). If we are lucky, restarted A1 would be ready to handle requests soon enough to prevent troubles. Otherwise, it may most likely end up with a cascade failure of the system. The rule is simple: the lower the startup time, the higher probability of survival in such cases is.
Scenario #2: Additional instances
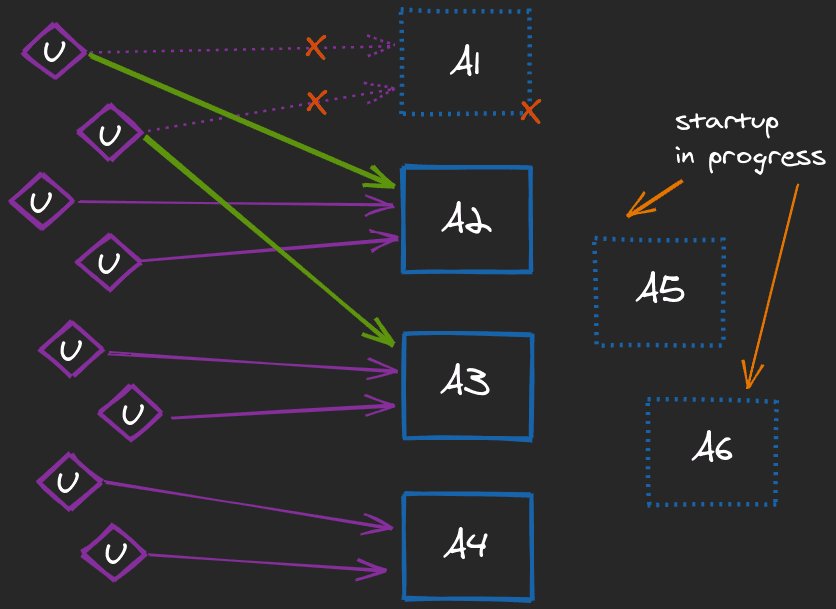
Apart from restarting the misbehaving instance A1, the Operator may also (even independently from restarting A1) spin up some additional ones (A5 & A6) in order to lower the workload across the nodes. Of course, such an action does not have to be postponed until the system is one step from failure. The whole concept of autoscaling is essentially about scaling early enough, based on the current (and expected) load. However, even in such cases, fast startups may be essential for reliability, as new instances are not immediately ready to handle requests.
As another example, let’s imagine an online store starting its Black Friday sale exactly at midnight. The expected traffic (measured by the number of users or their interaction) would probably look more or less like on the diagram below.
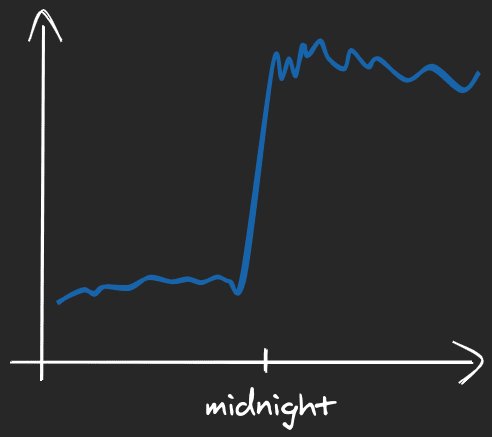
In terms of protecting the services from too high traffic by scaling up, autoscaling relies heavily on their startup time. If the new (additional) instances will become operable after any of the existing nodes would hit the Z limit, it may simply be too late to survive. So, even with autoscaling in place, a slow startup could have a negative impact on reliability.
Tip of the iceberg
Fast application startups are a kind of life insurance for our systems. However, as in life, having insurance in place does not mean we don’t have to be careful.
The system’s reliability in situations described before could be improved significantly in various different ways. With synchronous communication, we can use rate limiting, proper thread pools management, or non-blocking I/O. Alternatively, we may even switch to the asynchronous model completely (which has its own issues). With autoscaling in place, we may want to predict corner cases like the upcoming Black Friday (whenever possible) and overscale earlier. Another option could be to always overprovision (at least a bit) in order to be prepared for some unexpected traffic peaks.
Summary
Startup time may have a significant impact on the system’s reliability. Being able to restart failed instances quickly, or to spin up new instances before the traffic will exceed maximum capabilities may turn out to be crucial in many circumstances. For the modern distributed systems even the smallest details can play a huge role in terms of resiliency.