Single-partition Kafka topics
Apache Kafka has been designed with scalability and high-performance in mind. Thanks to its architecture and unique ordering guarantees (only within the topic’s partition), it is able to easily scale to millions of messages. However, there are some specific situations when using a topic with just one partition (despite being against mentioned features) might be a valid and simple solution to some complex problems of the distributed world.
In this post, I’d like to describe the so-called single-partition topic pattern and to list some valid use cases for it.
What is a single-partition topic?
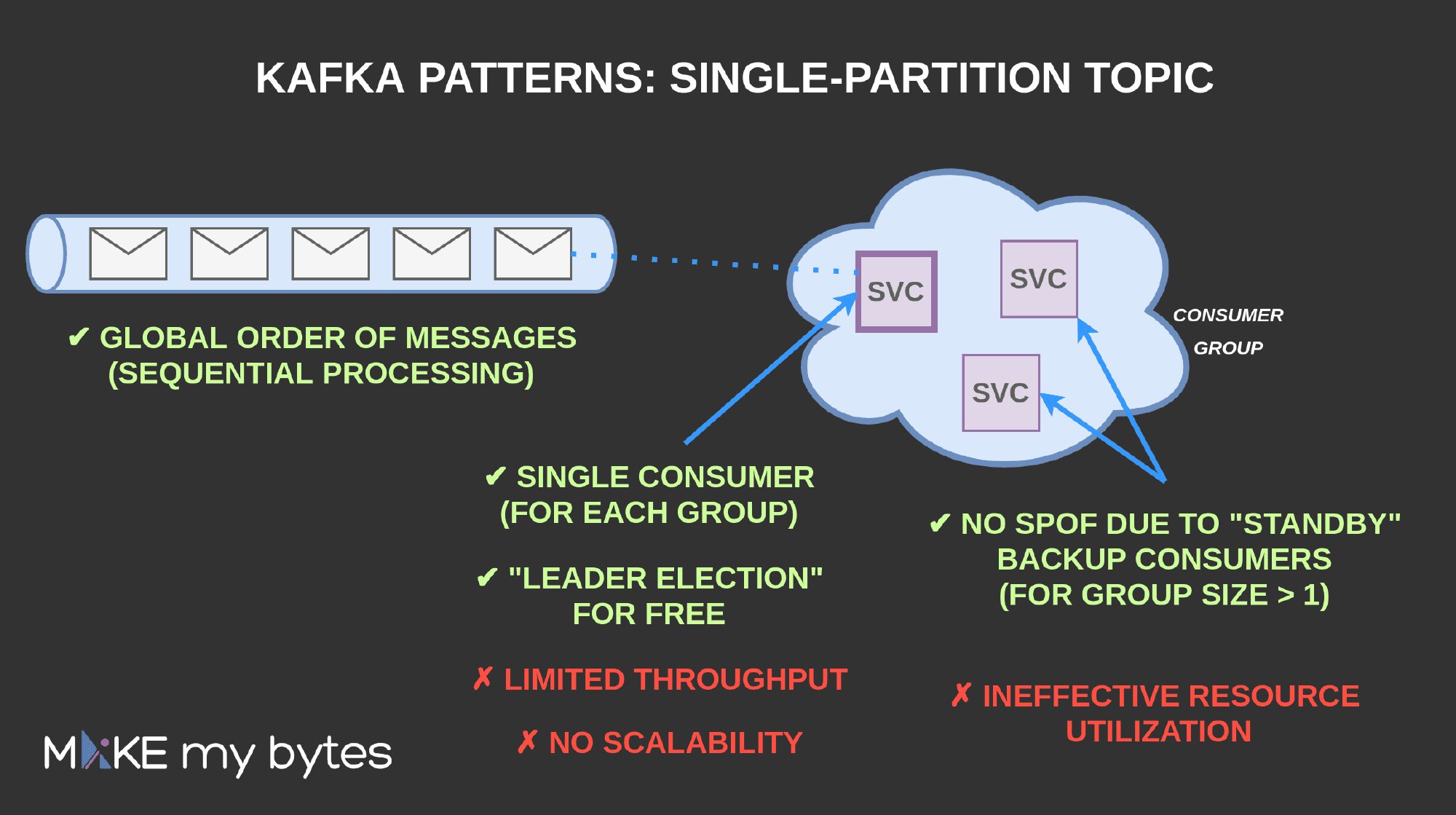
As its name suggests, a single-partition topic is a Kafka topic with only one partition defined. Such a choice has some straightforward limitations:
- only one consumer group member at a time may process the messages from such a topic, regardless of the group size,
- the maximum message processing throughput is the same as the maximum throughput of a single consumer, since the processing can’t be shared between the group members,
- for consumer groups of size N > 1, additional N-1 consumers remain idle.
In terms of processing throughput & overall scalability, we couldn’t pick worse than that. When facing intensive (a large number of messages) or expensive (high processing time for a single message) processing in a certain topic, a single-partition one is definitely not the right choice.
Additionally, giving up Kafka’s partitioning capabilities is rarely a good choice, so single-partition topics should be considered when designing a partitioning strategy is very hard or not possible at all (we will see an example of such use case later in this post).
On the other hand, such an approach has some additional strengths that combined with the low number of messages (within such topic) and fast processing time (of a single message) may be surprisingly useful. In other words, there are some valid (but rare) use cases for using a single-partition topic. Let’s review them in the context of the mentioned benefits.
Pro: Global order of messages
Since all the messages reside within the same partition, there exists a global (write) order of the messages within such a topic. This order (combined with a single consumer per group) guarantees, that messages will be processed one by one (sequentially).
This could be extremely useful when the processing of Nth message depends on the processing of the previous messages (N-1, N-2, and so on), but there is no way to partition dependent messages together upfront (when producing the messages).
As an example, let’s imagine a stream of changes being requested for a single table in a database (DB). Conceptually, such a stream is nothing more than a simplified transaction log of a single-table DB. Recorded changes must be applied in a way that “cause and effect” relationships, being the result of the order (e.g. creating row before removing it), must be preserved. Representing them as a single, ordered list of messages would enable the consumer to apply those operations sequentially in a conflict-free manner.
The existence of a global messages order is also heavily desired for many types of state-based schedulers. The only job of such a process is to decide, whether the operation (message) can be executed now (new message would be sent to the worker node) or stored for later (conflicts with a current state). Since the scheduler itself does not do the dirty & time-consuming job, a single-partition topic may be enough even in terms of delivering the required throughput. Simplified overview of such a solution has been presented on the image below.
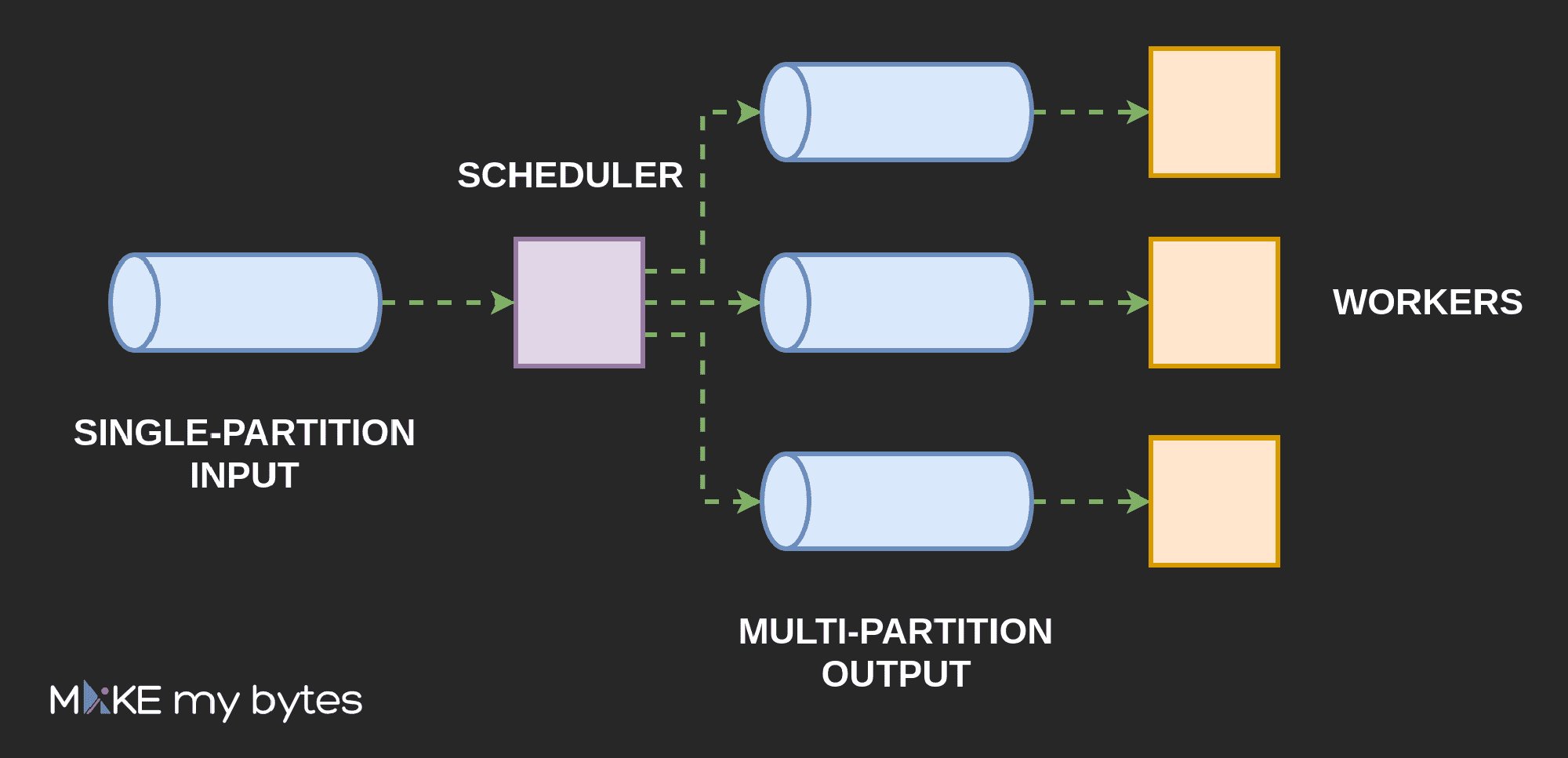
Pro: “Leader election” for “free”
Despite some subtle nuances between specific use cases, in general, the leader election problem comes down to selecting one node from N in a way that all N nodes agree on the same leader. There are different algorithms & tools that could solve this in a distributed system, but their overview exceeds far beyond the scope of this article.
What is important in the context of this article, is that with a single-partition Kafka topic, such a leader election happens when selecting a consumer from the consumer group. So, if you need to elect a leader node and you have Kafka already in place, you can think of expressing your problem as a single-partition topic (e.g. to avoid setting up additional infrastructure). Of course, not all of the problems could be expressed like this and all the already described limitations stand.
The pretty obvious use case is (again) scheduling. If we have N replicas of the same service with some scheduling job inside (e.g. find entries to execute in a DB and send them to the workers), we most probably need to make sure, that only one replica at a time will perform it. We can then use a single-partition topic as a queue of scheduling triggers and just let the selected consumer do the dirty job.
Pro: No Single Point of Failure
When the consumer group contains more than one consumer, a single-partition topic guarantees, that in case of consumer failure another one from the group will replace it. In other words, even without processing scalability, it enables us to avoid a Single Point of Failure.
Of course, this property comes at the price of ineffective resource utilization. As already pointed out, the remaining N-1 consumers (within a group of size N) remain idle for most of the time. That’s why a group size for such a case should be picked as an advised trade-off between fault tolerance and resource availability.
Single-partition topics usage tips
- In order to maximize the processing throughput, consider implementing a dedicated single-partition topic consumer, that does not process anything else. As a rule of thumb, just avoid any time-consuming processing there.
- When a single-partition topic’s consumer (single) writes to its own (exclusive) DB or any data store, most probably there is no need to use locking or any other concurrency control solution. Things like lowering the transaction isolation level may be interesting optimizations in such a case.
- Before selecting this pattern for usage, make sure that partitioning the messages within this topic is not an option for you. Since this approach plays somehow against Kafka’s capabilities just use it judiciously.
Summary
Despite the number of described limitations, the single-partition Kafka topic could be a very handy solution (in specific scenarios) for some complex problems of the distributed world, including sequential processing or leader election. As one of its most natural use cases, state-based scheduling could be considered. However, due to its scalability limitations, single-partition topic should definitely not be the pattern of the first choice - it’s enough to keep in mind, that this approach is available in our Kafka toolbox.